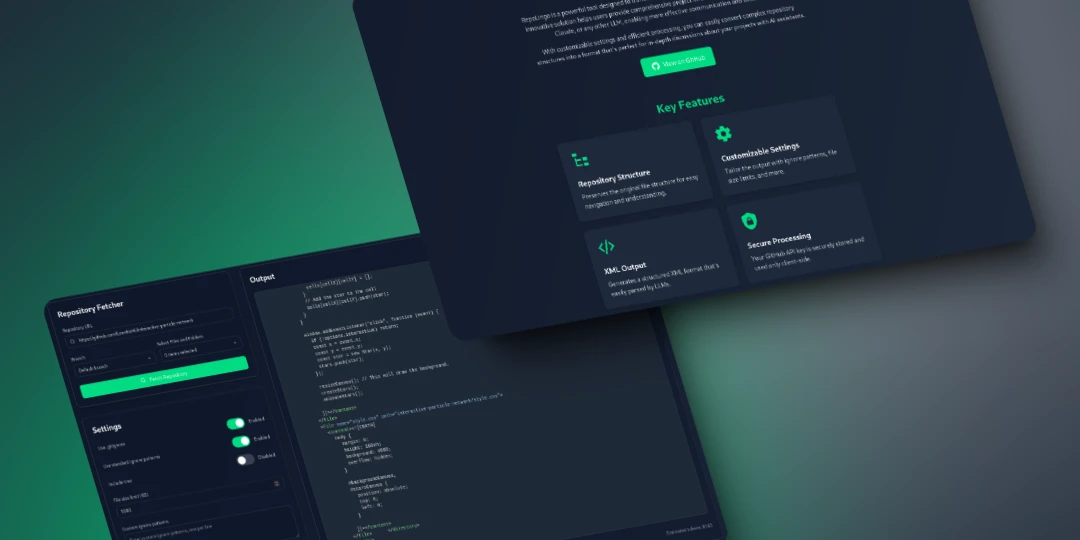
RepoLingo: Making Code Repositories LLM-Friendly
I kept needing to feed GitHub repos into LLMs, but raw repository data is full of noise. Too many irrelevant files, no structure, and you burn through your token budget on stuff that doesn’t matter.
What It Does
Point it at any public GitHub repo, and it:
- Fetches the repository
- Figures out which files matter
- Strips out noise (node_modules, build artifacts, etc.)
- Outputs structured XML with the code and its relationships
Technical Implementation
Built with Nuxt.js 3, Vue.js 3, and TypeScript. Uses Octokit to talk to the GitHub API. Also uses:
- highlight.js for code syntax highlighting
- gpt-tokenizer for token counting and optimization
- Tailwind CSS for responsive design
Customization Options
You can configure:
- Ignore patterns to exclude files you don’t need
- Select branch and file size limits
- Include or exclude tree structure
- Copy or download the generated XML
Who It’s For
Mostly developers who want to give AI assistants full project context, but also researchers analyzing code patterns and data scientists preparing code datasets.
XML Output Format
The XML format keeps the important stuff:
- File hierarchies and relationships
- Code content with syntax formatting
- Directory structures
- Import/export relationships between files
- File type and size metadata
<?xml version="1.0" encoding="UTF-8"?>
<llm_context>
<repository>
<metadata>
<name>LeonKohli/LeonKohli</name>
<description>Repository contents for LLM context</description>
<fetch_date>2025-03-01T22:45:40.499Z</fetch_date>
<branch>main</branch>
</metadata>
<contents>
<directory name=".github" path=".github">
<directory name="workflows" path=".github/workflows">
<file name="joke.yml" path=".github/workflows/joke.yml">
<content>
...
</content>
</file>
</directory>
</directory>
<file name="README.md" path="README.md">
<content>
...
</content>
</file>
</contents>
</repository>
</llm_context>
This helps a lot when you’re hitting token limits, since it prioritizes the most relevant code while keeping context intact.